Loading...
Searching...
No Matches
CROCK API
Architecture
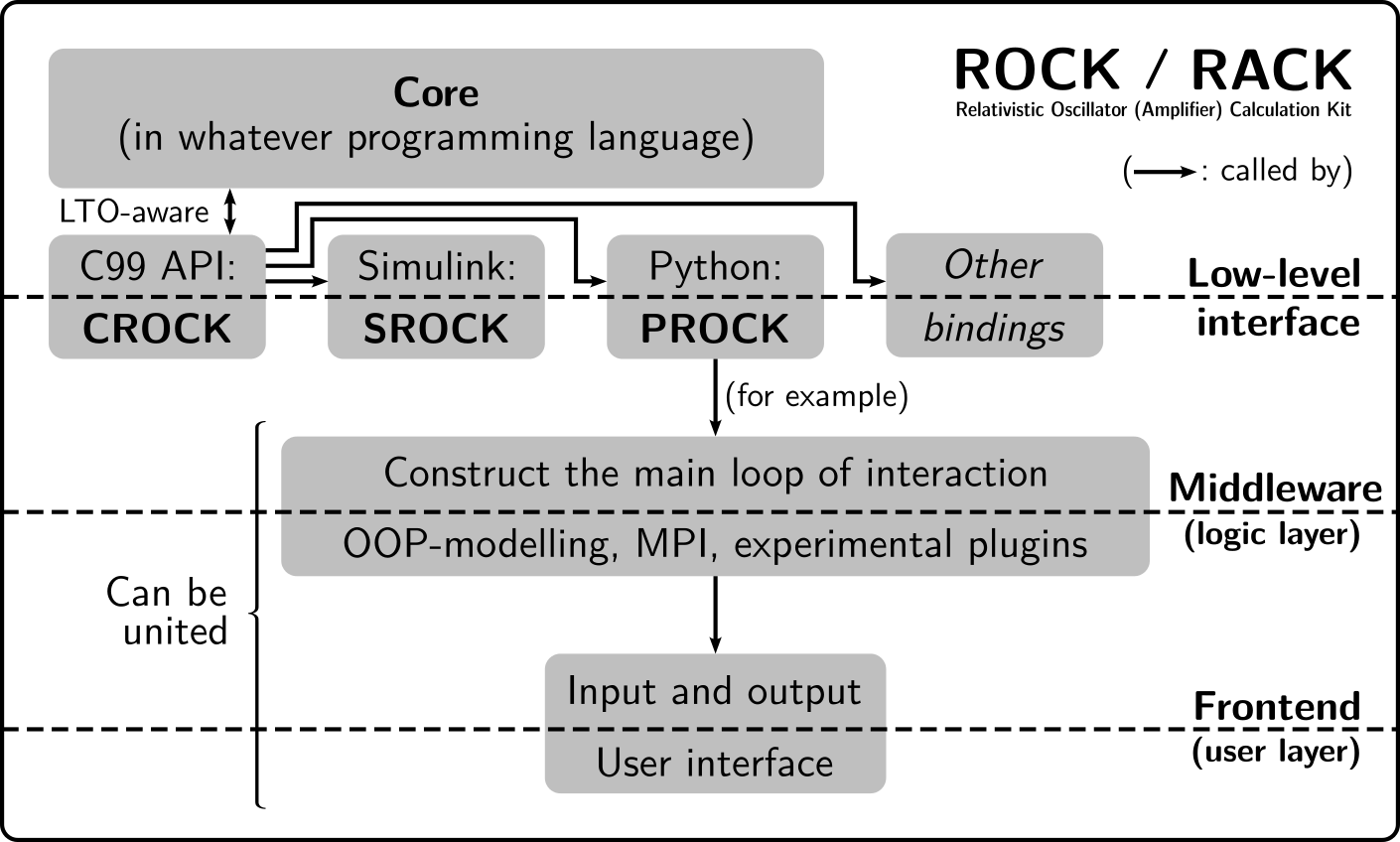
Architecture block diagram
Design Rules
Principles
- Minimized features for agility and maintainability
- Minimized technical debt in the mainstream development
- Well tested
Data
- SoA for GPU and SIMD optimizations
- Avoiding nested data structures in core for easier overview of the code logic
- The Core is pure and fully testable
- Random generator should not rely on global state.
- No allocation or freeing memory. Ideally, all memories, including the temporary buffers, should be prepared by CROCK or the bindings.
- If MPI will be used, it will be involved at a higher layer.
- Precision of all float numbers should be globally switchable
- Though, the calculation speed of single precision is the same as double precision on modern CPUs, single precision numbers still have advantages in
- GPU calculation
- MPI data transfer
- revealing the numerical instabilities hidden in the last few mantissa digits of double precision with less simulation steps
- However, the precision of 32-bit float
- is insufficient for many calculations
- requires relaxed thresholds for convergence check in search algorithms, as well as for setting up test cases
- The type long double with 80 or 128 bits can be used to
- check whether an instability is related to the precision
- obtain higher-precision solutions for setting up test cases
- Switchable precision of float numbers makes ROCK difficult to use BLAS/LAPACK. Furthermore, long double is not supported by BLAS/LAPACK at all.
- Though, the calculation speed of single precision is the same as double precision on modern CPUs, single precision numbers still have advantages in
- BLAS or not BLAS
- Field calculations involves linear vector operations (norms, inner products, filling diagonal rows by axpy) and tri-diagonal matrix operation (multiplication with vectors, cyclic reduction, etc.). They benefit from BLAS.
BLAS is less used in electron trajectory calculations. For example, evaluating Lorentz force is the hotspot, whose first step is to calculate the Larmor radius using:
const real rl = cc->bv_blt[BV(ib, B_UZ)] * cc->bv_blt[BV(ib, B_AP)]/ cc->bv_blt[BV(ib, B_W)]/ ((real)(-C_QEME) * c->input.vn_mag_axis[iz]);as well as other operations which cannot be expressed in BLAS operations.
- Profiler shows that the time for field calculation is less than 1% of the total time in a realistic simulation iteration.
- Therefore, BLAS may not bring too much performance improvement but introduces build dependencies.
Error Handling
- In the following context, errors include also warnings
- Abandon Solutions
- Callback loggers are avoided due to GPU code generation.
- Also, prints are not considered for side effects.
- Returning the error message as string pointer is possible but non-optimum, since it does not reflect the priority of errors.
- To simplify the error handling, the following rules are designed
- Error code (it is called in following the error number) is returned.
- There will be only one error returned each time.
- By multiple errors, only the one with the largest number is returned.
- Therefore, warnings are assigned with lower numbers than errors.
- Rules
Conventions
Generals
- APIs are in SI-units.
- Frequencies in APIs are 𝑓 rather than ω (while internal interfaces may allow ω for optimized performance).
- Since the word “spread” is vague, the definition “span” is used for the width of stochastic sampling. Spans are all relative and double-side. Span=0.2 means ±10% on each side of the reference value. Gaussian distributions are cropped at ±2σ, meaning that span≔4×σ/reference.
- Pitch factors and Lorentz factors are in Gaussian distributed.
- Guiding centers are uniformly distributed.
- Convention for the index in this document:
- Multidimensional arrays are indexed in the C-order.
- The notation of index range [0:N] includes 0 but excludes N, like the Python convention.
- Since the core is implemented in pure C, without typedef (except the global real type), the Linux kernel lower_case convention is applied for the identifiers except macro which are usually in UPPER_CASE.
- The term “nodes” are the mesh nodes along the 𝑧-axis. Nodes are indexed by 𝑧, for example, as vn_* arrays. Note that vz_* is intentionally avoided since it is confusing with the velocity $𝑣_𝑧$.
- The word “size” is confusing, because it could have the following meanings. We take the first meaning due to the built-in function sizeof().
- The number of bytes
The number of elements in an array or vector
- The word “length” is confusing, too. We use the word length for
- String length, as in strlen()
- The physical length, like 1 meter
Suffixes
- *_cs (cs means cos and sin) are normalized complex numbers, which have the form of CPLX(cos(angle), sin(angle)). Since the sincos() calls are so costly, they have to be pre-calculated. Batched pre-calculations can be better vectorized, which further improve the performance. Then in loops the sincos(angle1+angle2) are evaluated by complex multiplications of sincos(angle1) and sincos(angle2) .
- *_omp marks internal functions which contains OpenMP/multithread parallelization, in order to avoid nested multi-threading.
- The invoker should not inherate this suffix.
- APIs (cr_*) are OMP by default. Therefore should not contain this suffix.
- *_offload are the GPU-offloaded variant of functions, whose arguments are host pointers and variables.
- *_gpu are the GPU functions (not the kernels!), whose arguments are device pointers and variables.
Prefixes
- Functions of CROCK/CRACK APIs have the common prefix cr_*. In order to
- Distinguish the API and its proxied internal core function, which may have slightly different arguments.
- Avoid polluting the namespace of the caller (mid-ware/frontend) program.
- dim_ stands for dimension, which may also cause confusion. This word is used for:
- “Length” of a vector, i.e. the number of elements in a vector (which can be a row or column of a matrix), or the total number of elements in a matrix.
- Point: 0D, line: 1D, surface: 2D, volume: 3D etc., however, in this case the word “dimension” is shortened as d or D, rather than dim.
Shape of a multi-dimensional array.(We choose the word “shape” for that.)
- num_ generally indicates discrete numbers (typically integers). Difference to dim_ is that dim_’s are directly related to the data storage.
- make_ is just a universal word indicating an action (i.e. function / procedure).
- make_* is more preferable than
- get_* since those actions are more complicated than usual getters;
- calc_* since heavy calculations are not always required.
- The outputs are usually passed by pointers.
- These functions usually return error codes, see section Error Handling.
- Memory (de)allocation should not pass through the boundary of a make_* function.
- make_* is more preferable than
- tdm_* are related to Tri-Diagonal-Matrix, which consists of dim_z rows.
- The dimension of a Tri-Diagonal-Matrix is DIM_TDM(dim_z) = 3*ROCK_STRIDE(real,dim_z)
- opt_* are optional (NULLable) input or output parameters.
- Regarding SoA layouts:
- vn_* are vector(s) of nodes indexed by [iv, in], which has the shape [N, dim_z].
- vm_* are value(s) of modes indexed by [iv, im], which has the shape [N, dim_m].
- For waves, the index order mvn_* applies.
- A variant of mvn_* is mv_tdm_*, where tdm is the "spatial" coordinate instead of the raw node.
- For beamlets, specific index orders different from mvn_* are applied.
API Arguments
To be simple, data are stored in raw 1D vectors, which can be reshaped into multi-dimensional arrays. The following table contains the conventions of the variables which appear as arguments.
| Name | Type | Shape | Description |
|---|---|---|---|
| beam_init | real | [DIM_BEAM_INIT] | The statistic initial parameters of beams, see enum ROW_OF_BEAM_INIT. |
| bvn_blt_trj | real | [dim_b, DIM_BLT_TRJ, dim_z] | Beamlet trajectory, see enum ROWS_OF_BLT_TRJ |
| dim_b | size_t | scalar | Number of beamlets |
| dim_bcc | size_t | scalar | Dimension of radial grids for beam coupling coefficients |
| dim_m | size_t | scalar | Total number of modes |
| dim_z | size_t | scalar | Number of mesh nodes |
| mv_tdm_zk | real | [dim_m, DIM_TDM(dim_z)] | FEM matrix operation (Mz-Mk) for each mode |
| mvn_env | cplx | [dim_m, dim_z] | State of the envelope |
| mvn_mod | real | [dim_m, DIM_MOD, dim_z] | Multi-mode collection of vn_mod |
| mvn_src | cplx | [dim_m, dim_z] | Excitation (source) for the envelope equation without FEM-weighting (Unit in TE-mode: V/m^2) |
| mvn_uuload | real | [dim_m, dim_z] | "Very" unscaled ohmic load, [abs(mvn_env[m])^2 × mvn_uuload for m in modes] results in vn_uload |
| num_azi | int16_t | scalar | Azimuth mode number, whose sign represents the co- and counter-rotation |
| num_rad | int16_t | scalar | Radial mode number, whose negative sign is reserved for TM-modes |
| nvmh_bcc | real | [dim_z, dim_bcc, dim_m, DIM_HARM] | The grid of beamlet coupling coefficients where the v axis is an equidistant grid of radial span |
| tdm_c | real | [DIM_TDM(dim_z)] | FEM matrix Mc |
| vm_bc | cplx | [DIM_BC, dim_m] | Boundary condition, see enum ROW_OF_BC |
| vm_bd | cplx | [DIM_BD, dim_m] | Boundary data, which is dU/dz at left and right boundaries, see enum ROW_OF_BD |
| vm_bp | real | [2, dim_m] | Boundary phases, for the transient updating of boundary condition, [0, :] are the left side while [1, :] are the right side |
| vm_cf | real | [dim_m] | Carrier frequency in Hz (caution: not omega!) |
| vm_cp | real | [dim_m] | Carrier phase in rad |
| vm_df | real | [dim_m] | Delta frequency (drift of carrier) in Hz |
| vm_num | int16_t | [2, dim_m] | [0, :] = vector of num_azi while [1, :] = vector of num_rad |
| vm_rfc | cplx | [dim_m] | (Complex) Resonance Frequency of Cold cavity |
| vn_blt_avg | real | [DIM_BLT_AVG, dim_z] | Averaged beamlet data at each node, see enum ROWS_OF_BLT_AVG |
| vn_mod | real | [DIM_MOD, dim_z] | Parameters of a single mode along the 𝑧-discretization |
| vn_mrs | real | [dim_z] | Mesh Refinement Score of vn_z, a high value means the mesh is too coarse. The score at vn_mrs[i] indicates the mesh segment between vn_z[i] and vn_z[i+1] |
| vn_uload | real | [dim_z] | Unscaled ohmic load, vn_uload / sqrt(sigma) is the true load |
| vn_z | real | [dim_z] | Nodes of 1D discretization of 𝑧-axis |
IMPORTANT We treat num_azi=0 as having the same effect as a positive num_azi. (This choice is flexible but must be consistent.)
Arguments are sorted in the order (skip the element if not applicable):
- Individual inputs, e.g., time step
- Conventional inputs, in the order of
- Inputs depending only on mode
- dim_m
- vm_* (excluding mv_tdm_*)
- Inputs depending only on node
- dim_z
- vn_* (or their rows) in the order of
- vn_z
- vn_num
- vn_mod
- tdm_*
- Inputs depending only on both mode and node
- mv_tdm_*
- mvn_*
- Inputs depending only on beamlet
- dim_b
- Inputs depending only on mode
- [in,out] variables (and dimensions)
- [out] variables (and dimensions)
Miscellaneous
- sincos() is not in C standard and therefore not used. Neither is the pair manually calculated by sqrt. The optimization to a sincos() call should rely on the compiler. So, check in the profiler whether sincos() is used instead of individual sin() and cos().
- [C99] Complex I:
- Just using I or _Complex_I for re+im*Idoes not work on Visual C. Besides, since GCC lacks of _Imaginary_I and uses _Complex_I, INF*I = INF*(0,1) == (NAN,INF) rather than (0,INF).
- If I needs to be involved, use the own-declared II instead of I, see the code docs.
- [C99] An own implementation of CPLX is used instead of CMPLX for the following reasons:
- CMPLX in GCC's header (as standard in most Linux) is hidden from clang due to the missing of GCC-specific version macro __GNUC_PREREQ.
- CMPLX is not generalized for CMPLXF and CMPLXL.